DatadogでAzure Application Gatewayのバックエンド正常性監視(Azureのメトリック監視)
DatadogをAzureのテナントと接続する事で、Azureのリソース(Application Gateway等)のメトリック監視やダッシュボード表示を行う事が出来ます。
DatadogでAzureリソースのダッシュボード作成、メトリック監視設定を実際にやってみて手順を確認してみました。
設定対象はAzure Application Gatewayのバックエンドプールの正常性(正常なホスト(Healthy host count))としてみました。
なお、Azure Monitorを使ったAzure Application Gatewayのバックエンドプールの正常性監視はこちらに記載しています。

また、AzureとDatadogの接続についてはこちらに記載しています。
DatadogでもAzure Application Gatewayのバックエンド正常性メトリックを取得出来る
まずAzure Application Gatewayの正常性プローブの変化は、バックエンドプールにある正常なホストの数の変化で分かります。
-
-
- 正常なホスト(Healthy host count)の数が0の場合は、すべてのバックエンドプールに問題が発生しており、サイトが表示されない状態
-
次にDatadogで取得されるAzure Application Gatewayのメットリック値を確認します。
Datadog公式サイト(Application Gateway)
サイトを確認すると、azure.network_applicationgateways.healthy_host_countという項目があり、正常なホスト(Healthy host count)がDatadogでも確認出来そうです。
Datadogでダッシュボードを作成してAzure Application Gatewayの正常なホスト(Healthy host count)の数をグラフ表示する
DatadogでApplication Gatewayの正常なホスト(Healthy host count)を表示してみます。
まずメニューのDashboards>New Dashboardを選択します。
Crate dashbordが表示されますので、ダッシュボード名をつけてNew Screenboardを選択します。(今回の場合はどちらを選択しても問題ないです。)

空のダッシュボードが作成されますので、Edit Widgetsを選択しApplication Gatewayのウィザードを追加します。

ウィジェットを表示する項目の編集画面が表示されます。今回は時系列の状態をグラフ表示させたかったので、Timeseriesを選択しました。
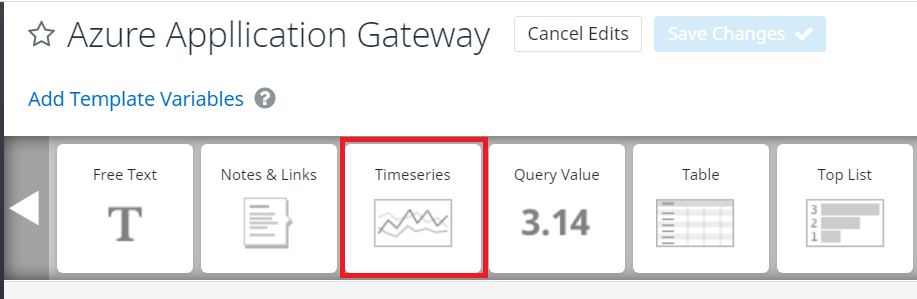
次に取得する値の設定画面が表示されます。Application Gatewayの正常なホストを数をバックエンドプール単位で表示しますので、以下の値を設定します。設定が完了したらSaveを選択します。
-
-
- Metric:azure.network_applicationgateways.healthy_host_count
- avg by:name、backendpool
-
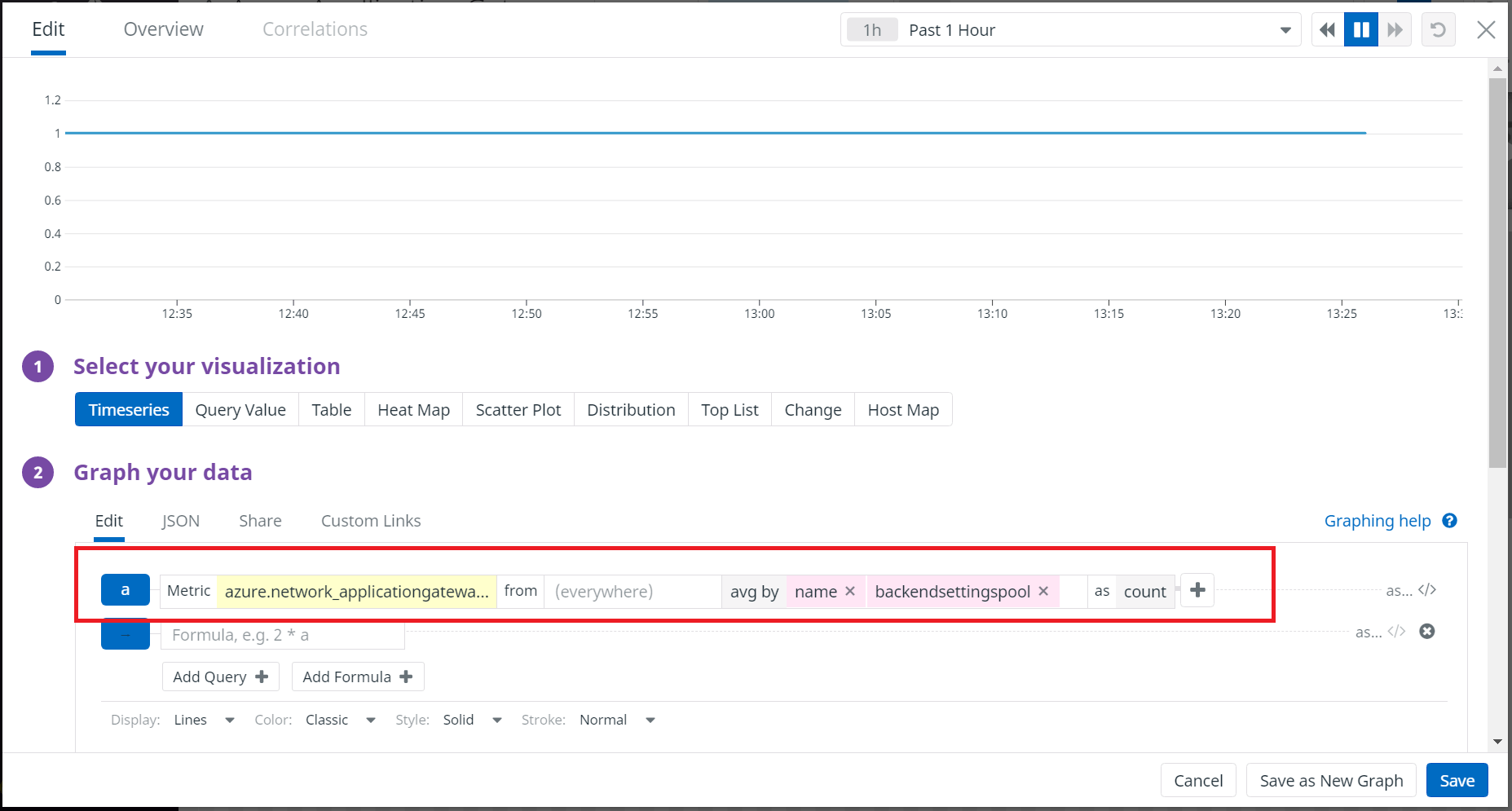
ダッシュボードの編集画面に戻りますので、Save Changesを選択して保存します。
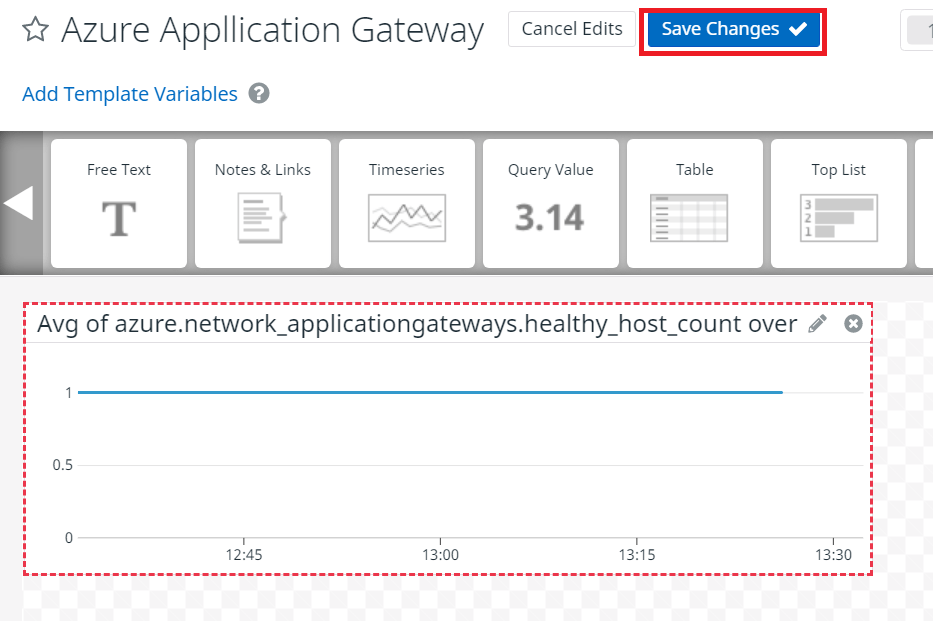
これで設定は完了です。作成したダッシュボードを表示させると下記のように表示されます。
DatadogでAzure Application Gatewayのバックエンドプール監視をしてみる(正常なホスト(Healthy host count)の数で監視する)
DatadogでApplication Gatewayの正常なホスト(Healthy host count)の監視設定をしてみます。
今回の監視設定は下記の条件で実施します。
-
-
- 監視対象:Azure Application Gateway
- 監視項目:Healthy host count
- 監視間隔:5分
- ワーニング発出条件:2以下の場合(5分間で正常なホストカウントが2以下の場合)
- アラート発出条件:0の場合(5分間正常なホストが存在しない場合)
-
まずメニューのMonitors>New Monitorを選択します。
Select a monitor typeが表示されますので、Metric(今回はメトリック監視なので)を選択します。

Select a metric to monitorの画面が表示されます。実際の監視設定を行います。
まずChoose the detection methodを選択になります。今回はThreshold Alertを選択します。
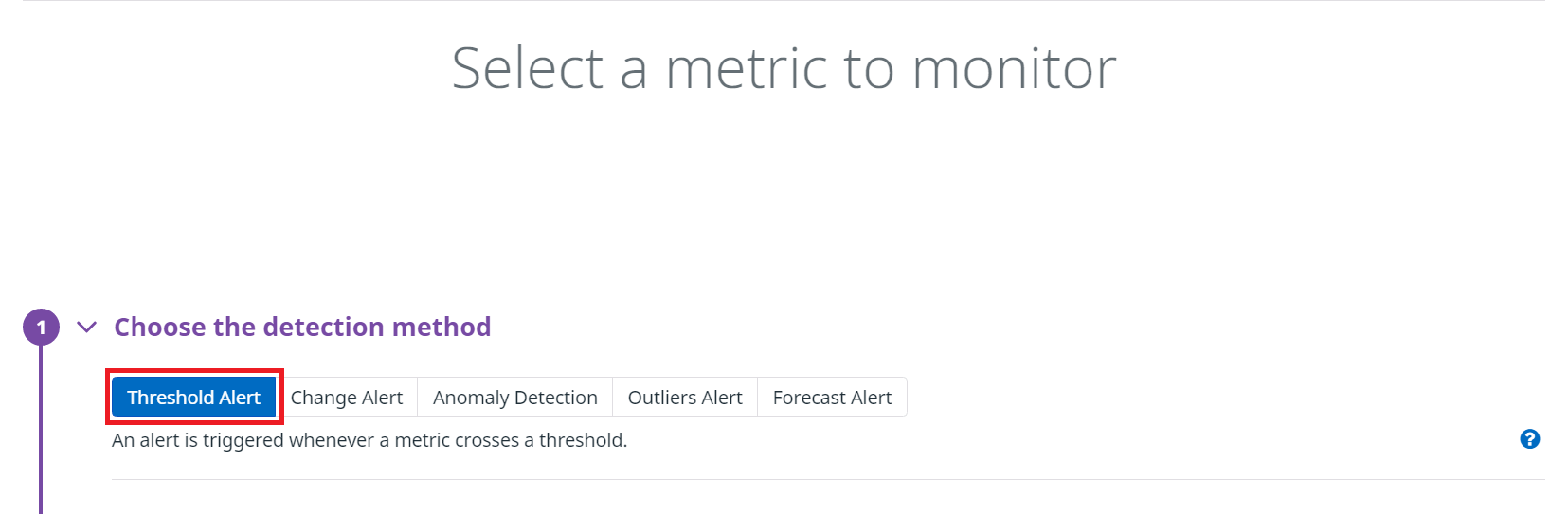
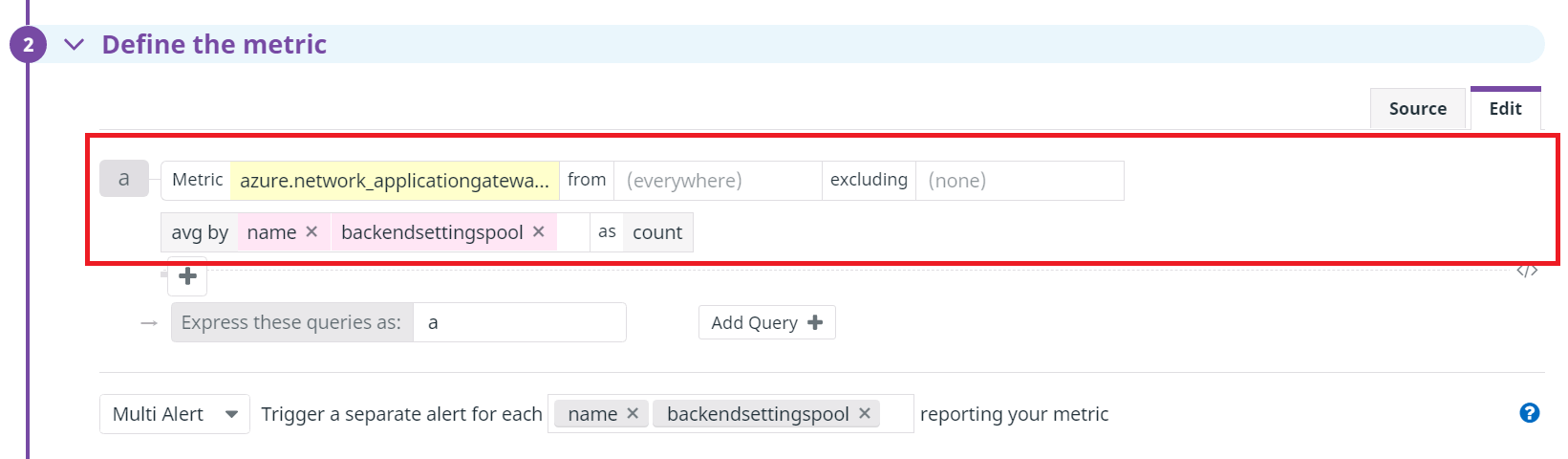
次にDefine the metricで監視対象の設定を行います。
Application Gatewayの正常なホストを数をバックエンドプール単位で監視しますので、以下の値を設定します。
-
-
- Metric:azure.network_applicationgateways.healthy_host_count
- avg by:name、backendpool
-
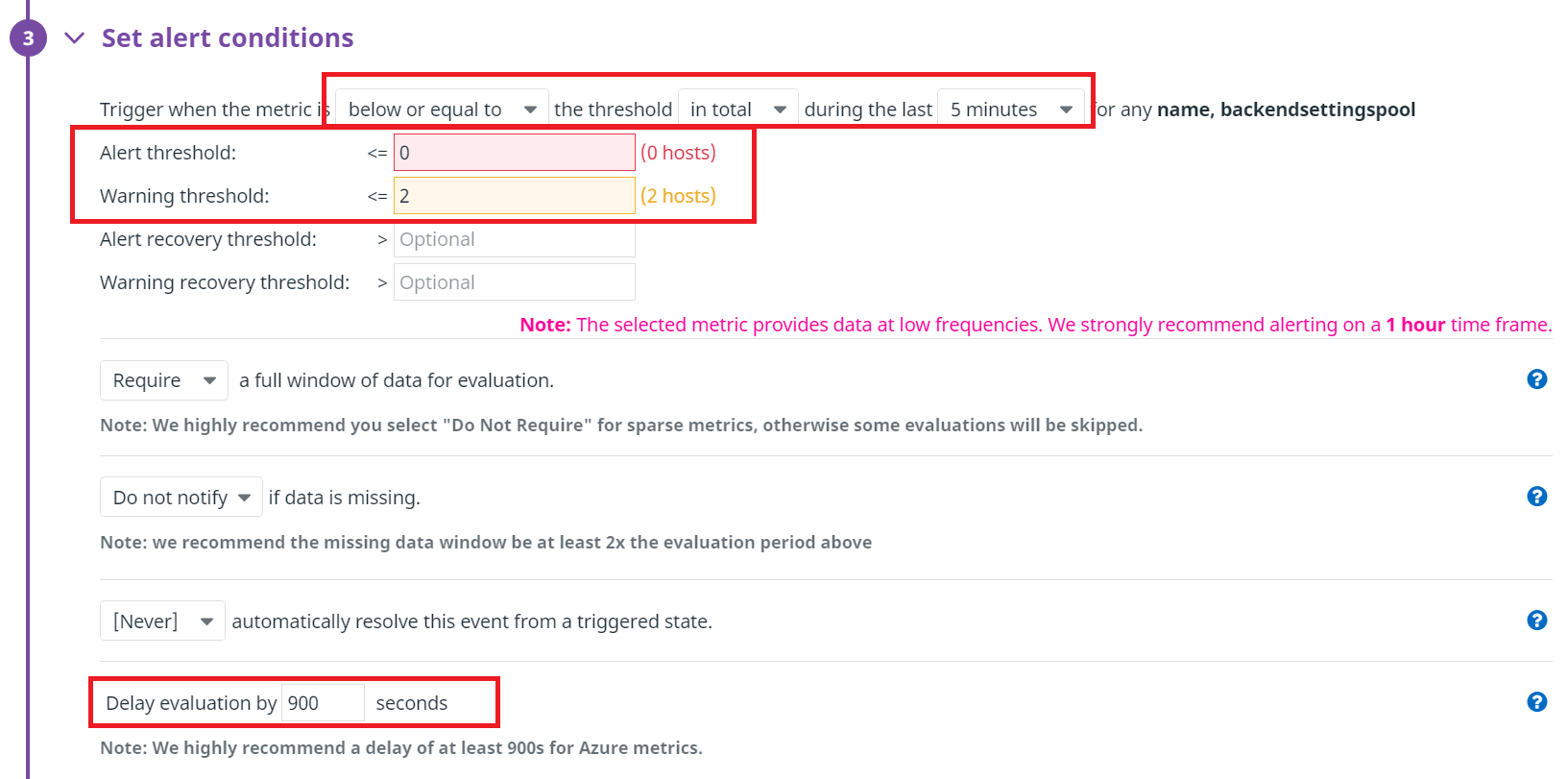
Set alert conditionsでアラート発出条件を設定します。
今回は以下の条件で設定します。
-
-
- Triger when the metric
- below or equal to
- in total
- 5 minutes
- Alert threshold:0
- Warning threshold:2
- Delay evaluation by:900
- Triger when the metric
-
5分間で正常なホスト(Healthy host count)が0の場合(5分間通信が行えない状態の場合)、アラートとしています。
また、Azureの場合、DatadogがAzureからメトリック収集する間隔が5分間隔になります。
その為、Delay evaluation byを設定しないと、直近5分間応答がない状態になってしまう為、Delay evaluation byを設定します。(今回はDatadogの推奨設定である900秒(15分)を設定しています。)
※Delay evaluation byを設定しているので実際にアラート検出が行えるのは最大20分後になってしまいます。(実際の利用にあたっては監視間隔を含めてチューニングが必要になります。)
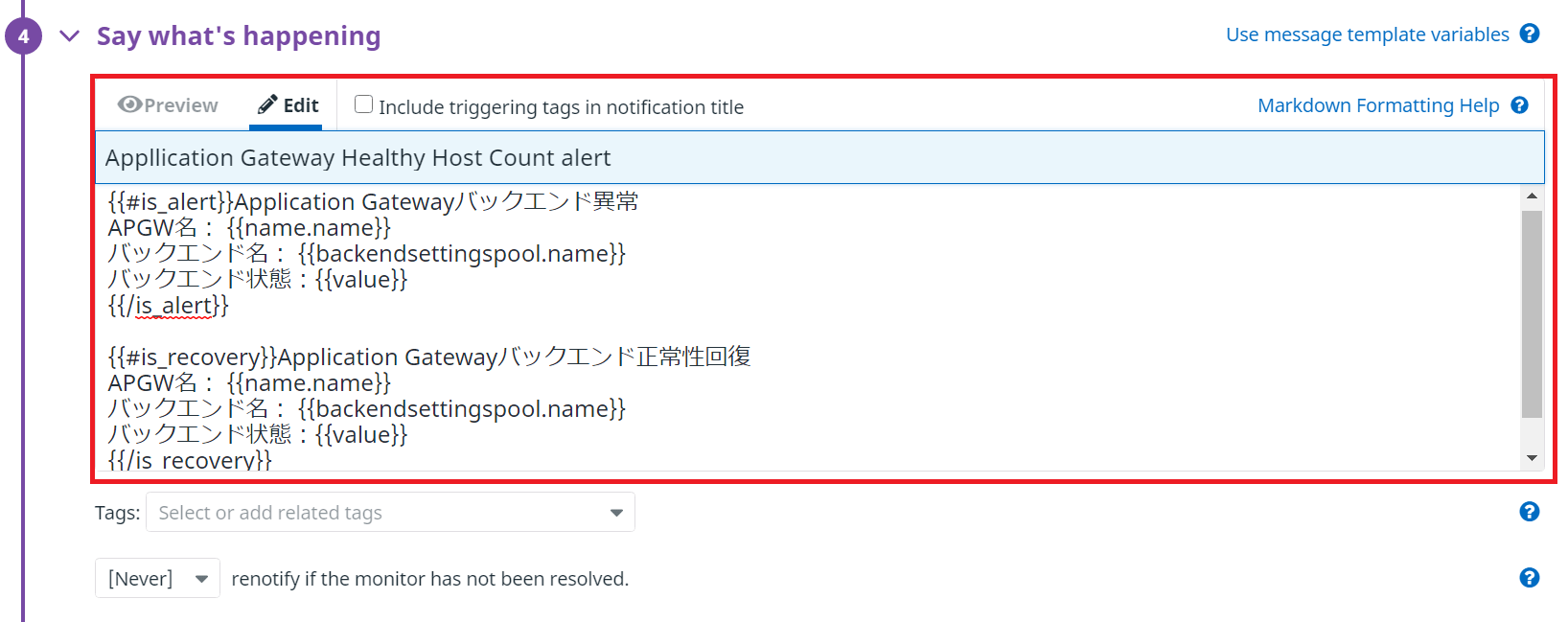
最後にSay what’s happeningで通知方法を設定します。今回は以下の条件で設定しています。
-
-
- 通知メールタイトル:Application Gateway Healthy Host Count alert
- メール本文:
{{#is_alert}}Application Gatewayバックエンド異常
APGW名: {{name.name}}
バックエンド名: {{backendsettingspool.name}}
バックエンド状態:{{value}}
{{/is_alert}}{{#is_recovery}}Application Gatewayバックエンド正常性回復
APGW名: {{name.name}}
バックエンド名: {{backendsettingspool.name}}
バックエンド状態:{{value}}
{{/is_recovery}}
@Mailアドレス※is_alertでアラート発生時、is_recoveryでアラート回復時の内容を設定します。
-
Saveで保存します。これで設定は完了です。
実際にアラートを発生させてみると、こんな感じでアラートメールが送信される事が確認出来ました。
—実際のメール内容—
[Triggered] Application Gateway Healthy Host Count alert
Application Gatewayバックエンド異常
APGW名: Application Gateway名
バックエンド名: バックエンドプール名
バックエンド状態:0.0